Hi, I’m Katrina, a Senior Product Developer at Titansoft. My role goes beyond just development—I often find myself acting as the glue within the team, keeping track of progress, supporting teammates, and ensuring things are moving in the right direction.
I’m involved in gathering requirements, building solutions, providing support, and working both collaboratively and independently to deliver outcomes.
Introduction
In many teams, delivery is measured by how quickly a feature goes live. In my department, I learned that go-live is only part of delivery. Support readiness, shared understanding, and communication matter just as much.
We have two development teams working under the same Product Owner, sharing one backlog and maintaining the same applications. In our context, what we work on consists of multiple applications and integrations under the same domain. On paper, this sounds straightforward. In reality, it is much more fluid.
We follow Agile practices such as sprint planning, SP1/SP2 discussions, sprint reviews, and retrospectives. However, real work does not always follow a strict structure. Because of deadlines and operational needs, work is often distributed based on urgency and availability rather than team boundaries. Multiple features are developed in parallel while production support continues at the same time.
Over time, I realized that delivery in this environment is not just about implementation. It is about how well the team can support, understand, and evolve what has been built.
Why the Environment Is More Complex Than It Looks
Our department maintains several applications at once. These systems serve customers with different working hours, sometimes overlapping with our off-hours or even midnight.
We also integrate with many third-party providers and expose APIs to external users. This adds complexity beyond feature development—we must ensure stability, compatibility, and clear communication across systems and integrations.
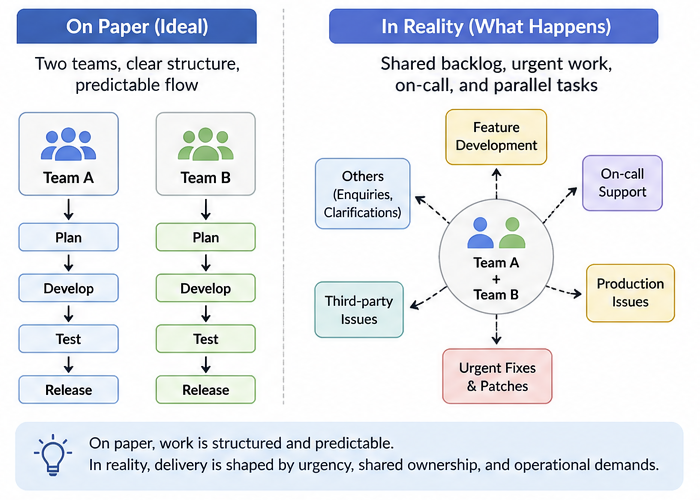
On top of that, we run a daily on-call rotation. During working hours, developers focus on delivery, but one PD is always responsible for handling production issues and enquiries. Because the scope of systems is large, this role requires constant context switching and broad understanding.
This made me realize that release speed alone is not a good measure of delivery quality. Delivery is also shaped by how well we respond to real production situations.
Delivery Does Not End at Go-Live
A feature is not truly delivered when it goes live. It is only complete when the team can support it.
I remember one on-call rotation where a production issue came from a third-party integration. From our system’s perspective, it looked like a failure on our side. I had to trace logs, read the code, and coordinate with the third party under time pressure. Eventually, we confirmed the issue was external, but the process was stressful and time-sensitive.
That experience made something clear: documentation alone is not enough if only one person understands how the application works.
In our department, developers usually own a feature from development through release and often support it during an initial stabilization period. For larger features, we create Confluence documentation and share knowledge through team discussions or technical sessions.
But the real goal is not documentation—it is shared understanding. Support is a team responsibility. If only the original developer understands how an application works, the team cannot respond effectively.

Documentation Helps, but Code Is the Real Source of Truth
This environment also changed how I view documentation.
Documentation is valuable, but it is not always complete or up to date. It often describes intended behavior, but not every implementation detail. In large systems, some logic is too complex or interconnected to fully capture in writing.
Because of that, I learned not to rely only on documentation. Code and actual system behavior are the most reliable sources of truth.
Over time, I developed a habit of reading code and exploring systems beyond my assigned tasks. During support, I also began recording key findings to make future troubleshooting easier—not only for myself, but for others.
Why Bugs and Performance Issues Still Happen
Even with structured processes, issues still occur. Most of the time, the cause is not a simple coding mistake, but system complexity.
During planning, we define acceptance criteria and sometimes create flowcharts. These help align expectations, but they cannot capture the full system context. Relying only on written requirements can still leave gaps in understanding.
I saw this clearly in a performance-related case.
When releasing new features, we perform basic load testing to ensure the application behaves correctly. Our team is responsible for query design and how data is used, while database infrastructure is managed by another team. In practice, testing focuses on expected usage rather than large-scale production data.
Initially, everything works well. But as real data grows over time, the situation changes. Some datasets cannot be easily cleaned up, and queries that were once efficient begin to slow down.
In one case, a feature worked smoothly for a long time, but later caused slow responses and high database CPU usage. When we investigated, we found that the original design was no longer suitable for the current data size.
Nothing was technically “wrong” when the feature was first released. The issue appeared because real usage evolved.
This taught me that performance is not a one-time validation. It must be revisited as systems grow.
How We Share Knowledge in a Growing Environment
As our systems and integrations grow, knowledge sharing becomes more important—and more difficult.
For new third-party integrations, we assign a champion and a backup to handle communication and implementation. These owners document key details and share knowledge with the team.
This approach provides clear ownership and reduces confusion. If work pauses due to changing priorities, it can resume more easily because information is already structured.
At the same time, shared support does not mean everyone needs the same level of detail. A practical approach is to have clear owners with deeper expertise, while ensuring the wider team understands enough to support the system when needed.
Retrospective and Continuous Adaptation
Retrospectives are valuable only when they improve future behavior.
When similar issues occur repeatedly, we do not just fix them—we analyse root causes and adjust how we work. This may involve introducing new practices or removing ones that no longer fit.
We also collaborate across team boundaries, especially for complex issues such as performance optimization. Even though we are structured as two teams, effective delivery often requires broader cooperation.
Over time, I learned that the process is not fixed. It must evolve with the system and the team.
Learning to Work with Different Styles
Teamwork is not only about processes, but also about people.
Different developers work in different ways. Some prefer detailed information before starting. Others explore systems independently and learn through discovery. Both approaches are valid.
Effective collaboration comes from understanding these differences and working together, rather than forcing everyone into the same style.
Communication with the PO Is Part of Delivery
Communication with the Product Owner is also essential.
Although the PO sets priorities, developers often need to communicate directly with customers or third parties to clarify details. We also ensure that users understand how to use new features after release.
In this context, communication with the PO is not just status reporting. It supports transparency and helps align decisions across stakeholders.
Conclusion
The biggest lesson I learned is that delivery is much more than implementation.
In a shared environment, developers are responsible not only for building features, but also for supporting, explaining, and improving the applications they work on.
Two teams may share the same backlog and systems, but shared ownership only works when there is also shared understanding. That understanding is built through curiosity, communication, adaptation, and continuous learning.
In the end, sustainable delivery is not about how fast we build, but how well we understand and support what we build.
