Hi, I’m Jiang Han, a Product Developer at Titansoft. In my day-to-day work, I gather requirements from clients, and design, develop, and maintain software solutions for them. From time to time, I enjoy doing competitive programming as a hobby. I have a keen interest in how systems work beneath the surface, as it helps me appreciate the engineering behind them, and I often see concepts from competitive programming appear in these systems.
Back in university, many of us went through Data Structures and Algorithms. While some found it painful, others, including myself, found it elegant and enjoyable. Naturally, I once thought I would continue working closely with these concepts as a software engineer. In reality, we rarely implement data structures ourselves since most are already provided by libraries. However, understanding how they work is still important, as different structures come with different trade-offs. Choosing the wrong one is like using a chainsaw to hammer nails. It might work, but it is far from ideal.
In most applications, data is stored in a database, and its performance often becomes a critical bottleneck. Different databases are built on different underlying storage structures, each optimised for specific workloads. In this article, we will look at two common ones: B+ Trees and Log-Structured Merge Trees (LSM Trees), and why their differences matter in practice.
B+ Tree
Starting with Binary Search Trees (BSTs)
To support both efficient reads and writes, we need a data structure with good overall performance. A binary search tree (BST) is one such structure, where each node maintains an ordering: values in the left subtree are smaller, and values in the right subtree are larger. In an ideal case, this gives O(log n) time complexity for both reads and writes.
However, BST performance depends heavily on its shape. In the worst case, it can become skewed and degrade to O(n). Self-balancing variants such as AVL trees or red-black trees address this by maintaining balance through node rotations, ensuring consistent performance.
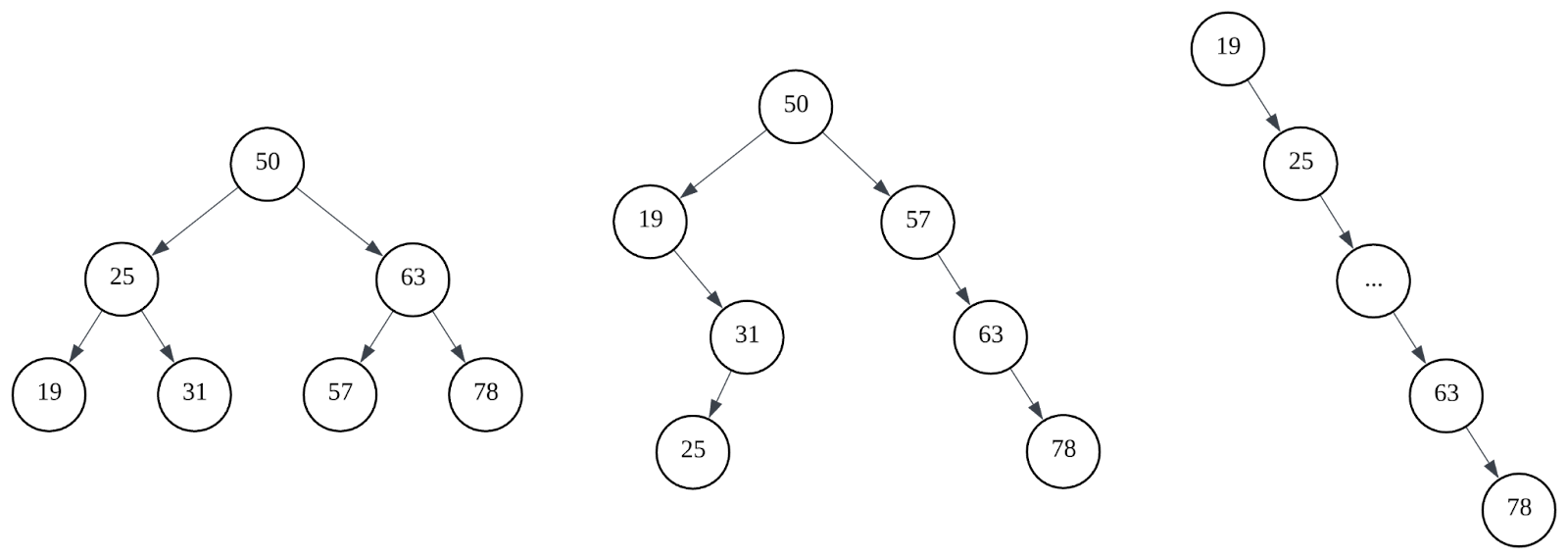
The problem is that these structures assume data resides in memory. In databases, data must be persisted to disk to satisfy durability requirements. Disk access is much slower and operates in fixed-size pages. Since BST nodes are small and have low fan-out with only two children, the tree becomes tall and requires multiple page reads to reach a leaf. In addition, BSTs have poor locality, which makes range queries inefficient. These limitations make them unsuitable for disk-based storage.
Moving on to B+ Trees
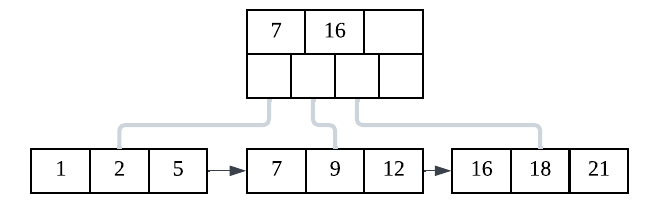
B+ Trees are designed to address these issues. Instead of storing a single key per node, each node contains multiple keys and child pointers, resulting in high fan-out and a much shorter tree. This reduces the number of page reads required to access data, which is crucial for disk performance.
A B+ Tree can be viewed as a variation of another data structure called a B-Tree. The main difference between them is that a B-Tree’s internal nodes can store both keys and values, while B+ Tree internal nodes strictly store only keys, and the key-value pairs are stored only at the leaf level of the tree. Additionally, in a B+ Tree, the leaf nodes are all linked together to form a linked list, which makes it very efficient for range queries. This is why databases prefer B+ Trees over B-Trees. Because each node maps closely to a disk page, both B-Trees and B+ Trees make better use of storage and improve locality. Keys within a page are stored in sorted order, and adjacent pages often contain neighbouring data, making range queries efficient.
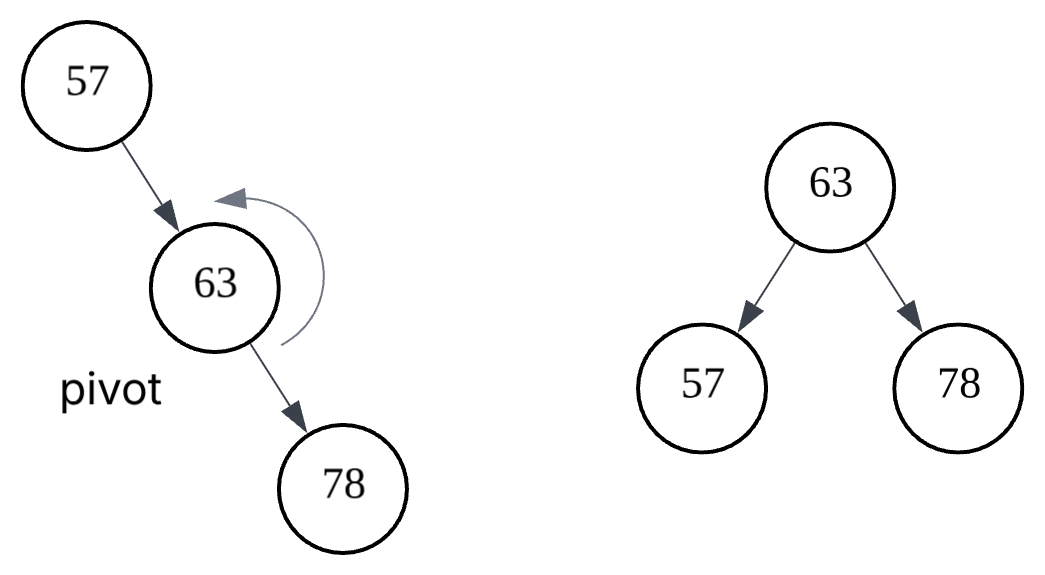
Balancing in a B+ Tree is simpler than in self-balancing BSTs. Instead of rotations, nodes are split when full and merged or redistributed when underutilised, keeping the tree balanced with minimal overhead.
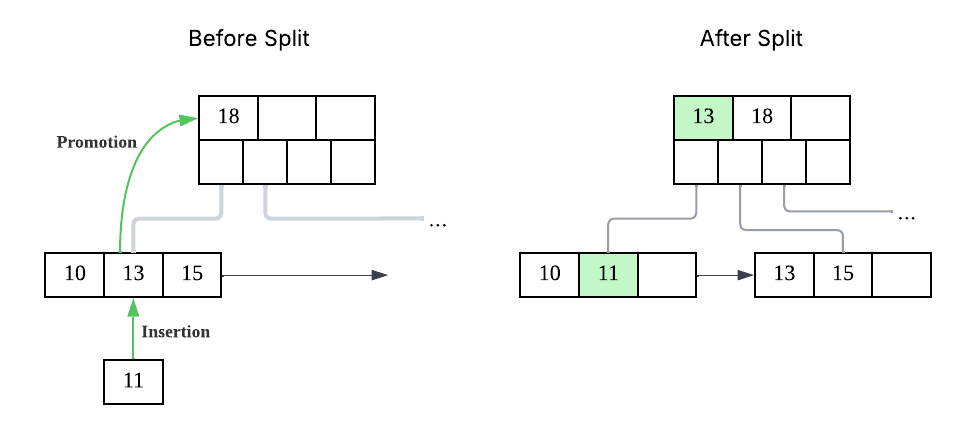
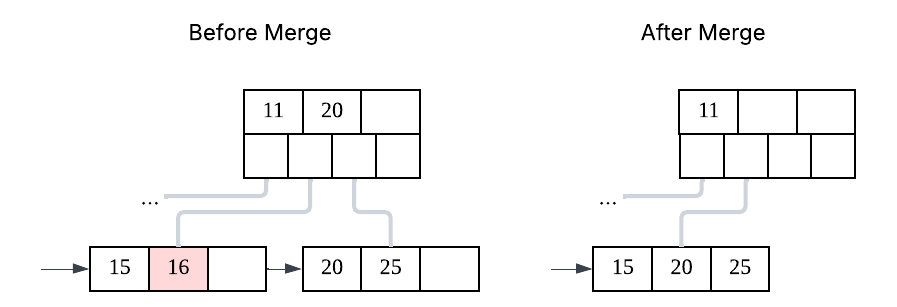
Over time, inserts, updates, and deletes can cause fragmentation within B+ Tree pages, leaving unused gaps that reduce space efficiency and may lead to unnecessary page splits. To address this, databases perform maintenance such as page compaction, merging underutilised pages, and occasionally rebuilding indexes. Some systems also run background cleanup tasks to remove obsolete data and keep the tree structure efficient without blocking normal operations.
In practice, databases rarely access disk directly for every operation. Instead, they use a buffer pool, an in-memory cache of frequently accessed pages, to significantly reduce disk I/O. Since B+ Trees group multiple keys within a page and have high locality, they benefit greatly from caching, as fewer page reads are needed. However, managing the buffer pool introduces challenges such as eviction policies, handling modified (dirty) pages, and coordinating concurrent access.
To ensure durability without incurring expensive random disk writes, databases use a write-ahead log (WAL). Before modifying B+ Tree pages, changes are first written sequentially to a log on disk. This allows the system to acknowledge writes quickly while deferring actual page updates. In case of a crash, the database can recover by replaying the log. While efficient, WAL requires careful coordination, such as managing log size and ensuring data is flushed in the correct order.
B+ Trees can be inefficient for write-heavy workloads, as inserts and updates may trigger page splits and require multiple random writes. Maintaining sorted order also adds overhead, making writes more expensive compared to append-only approaches. Over time, fragmentation and the need for maintenance can further impact performance. Concurrent writes can also lead to contention, especially when many operations target the same part of the tree. For example, in our case, inserting records ordered by timestamp caused hot-page contention, where many writes hit the same leaf page, leading to increased latency and high database CPU usage. We mitigated this by using a message queue to buffer and batch inserts, reducing contention and smoothing the write load. These limitations are why alternatives such as LSM Trees are often preferred for write-intensive scenarios.
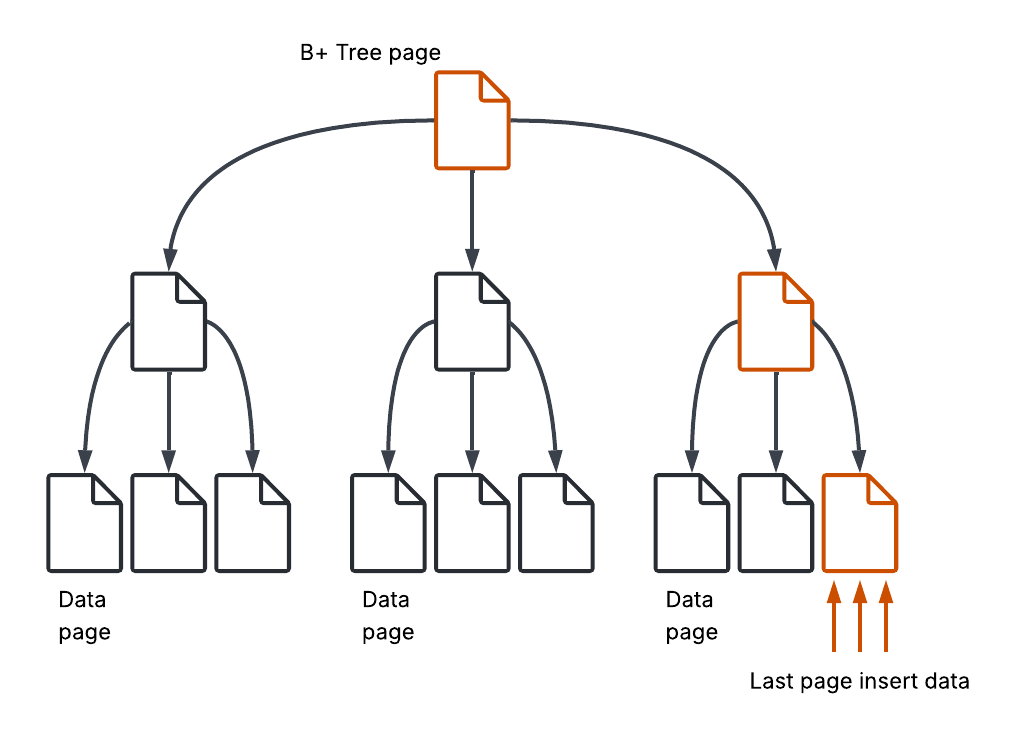
Log-Structured Merge Tree (LSM Tree)
A Different Paradigm of Data Storage
LSM Trees approach data storage using a different paradigm compared to B+ Trees. In B+ Trees, the current value of each record is stored and updates happen in place. An alternative approach, used by LSM Trees, is to store a sequence of updates rather than modifying data in place. Refer to the table below for an illustration using a wallet system.
| Event | Storing current value | Storing sequence of updates |
| Initial state | Wallet table: Balance100 | Statements table: IdAmount1+100 |
| Buy $5 laksa with wallet | Balance95 (overwrite 100 with 95) | IdAmount1+1002-5 |
| Final state | Balance = $95 (direct read from table) | Balance: $95 (sum the history of statements) |
Despite storing more data, this approach has several important advantages:
- Auditability: You can trace exactly how the current state was derived.
- Scalability: Past data is immutable, making it easier to replicate and distribute systems that primarily append new records.
- Recovery: In the event of a crash, the system can reconstruct the state by replaying the log.
This approach closely resembles accounting practices. Transactions are appended to a ledger, and corrections are made by adding new entries rather than modifying history. As the computer scientist Pat Helland famously said, “Accountants don’t use erasers; otherwise they may go to jail.”
In fact, we apply similar principles in some of our accounting-related systems. Having a full audit trail makes it easier to verify correctness, such as detecting missing or duplicate transactions affecting a wallet’s balance.
How LSM Trees Work
An LSM Tree is designed around sequential writes rather than in-place updates. Instead of modifying data directly on disk, writes first go to an in-memory structure called a memtable, which maintains sorted data. This is typically implemented using a balanced tree structure, although skip lists are also commonly used.
Once the memtable reaches a size threshold, it is flushed to disk as an immutable file called an SSTable (Sorted String Table). As the name suggests, an SSTable is a sorted sequence of key-value pairs. Because it is immutable, no in-place updates are required.
Over time, multiple SSTables accumulate on disk, often organised into levels based on size and age.
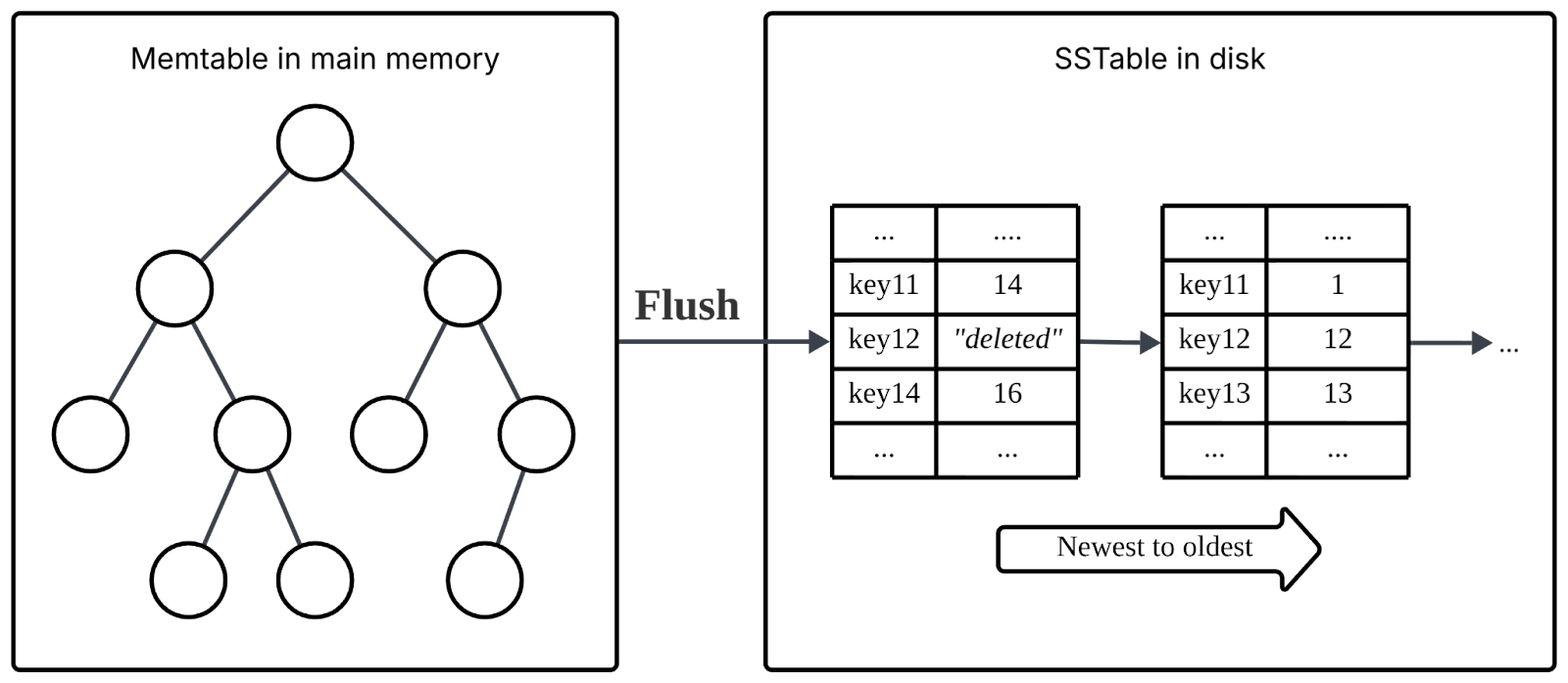
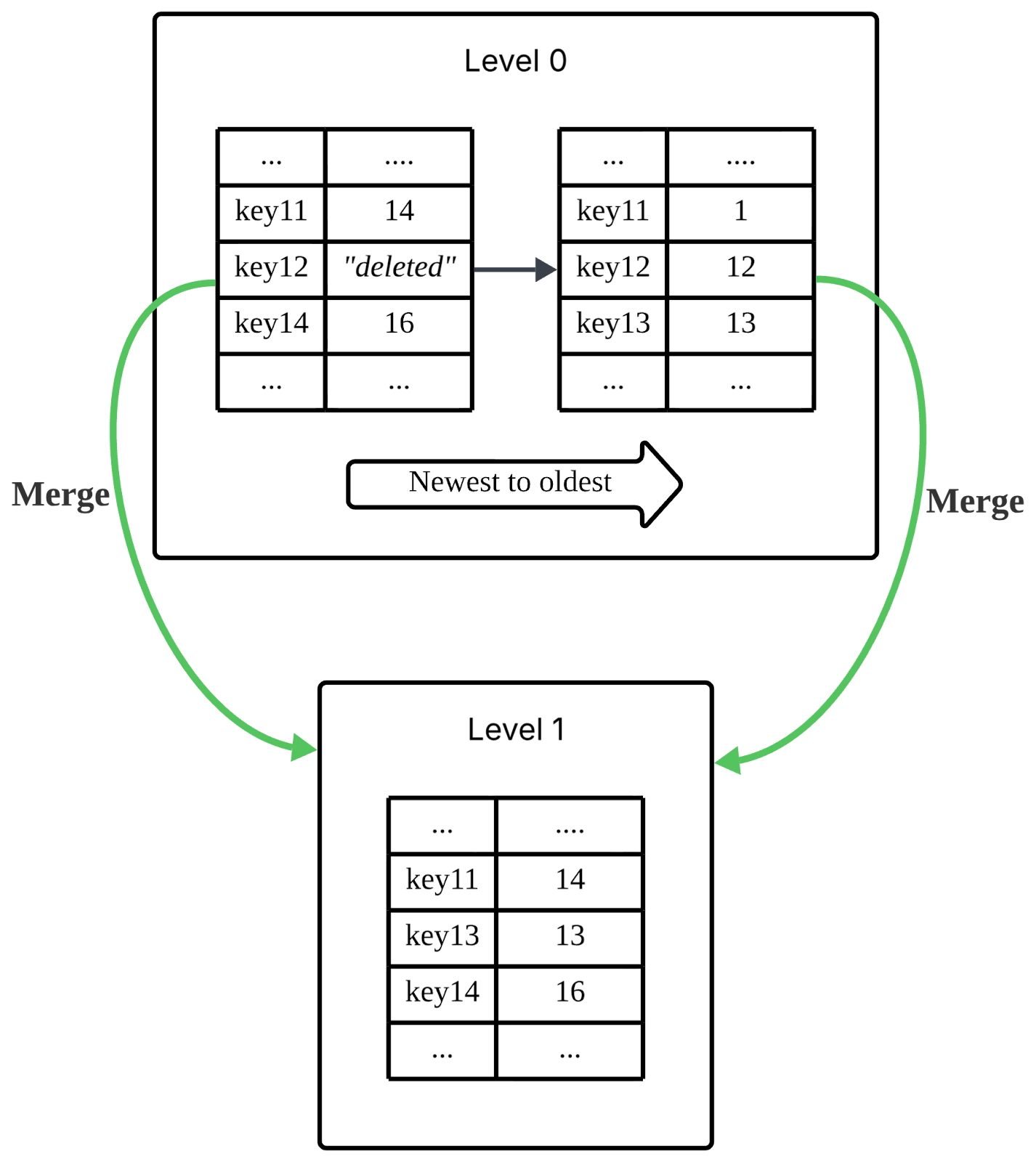
Reads in an LSM Tree are more complex than in a B+ Tree. To find a key, the system first checks the memtable, then searches through SSTables on disk, typically from newest to oldest. To avoid scanning every file, LSM implementations use additional structures such as Bloom filters (to efficiently tell you whether a key definitely does not exist or might exist in an SSTable) and sparse indexes (a memory-efficient index that helps locate where a key might exist within a file).
Writes are where LSM Trees excel. Instead of performing random writes across the disk, all writes are appended to a write-ahead log for durability and inserted into the memtable. When the memtable is flushed, data is written sequentially to disk as a new SSTable. Inserts and updates are effectively the same operation. For deletions, a special marker called a tombstone is written to indicate that a key has been removed.
Because SSTables are immutable, updates and deletes do not overwrite existing data. Instead, new versions are written, and old versions remain until cleaned up. This leads to multiple versions of the same key across different files, increasing storage usage and potentially affecting read performance.
To manage this, LSM Trees perform compaction, a background process that merges SSTables, discards obsolete data, and reorganises data into more efficient layouts. This is where the term “merge” originates. Since the tables are sorted, the process is similar to the merge step in merge sort and can be performed efficiently using iterators without loading entire files into memory.
LSM Tree Use Cases
LSM Trees are well suited for write-heavy workloads where high ingestion throughput is critical. Common use cases include logging, event streaming, time-series data, and analytics pipelines, where large volumes of data are written continuously and reads are either less frequent or can tolerate slightly higher latency. They are particularly effective when data is mostly appended rather than frequently updated in place.
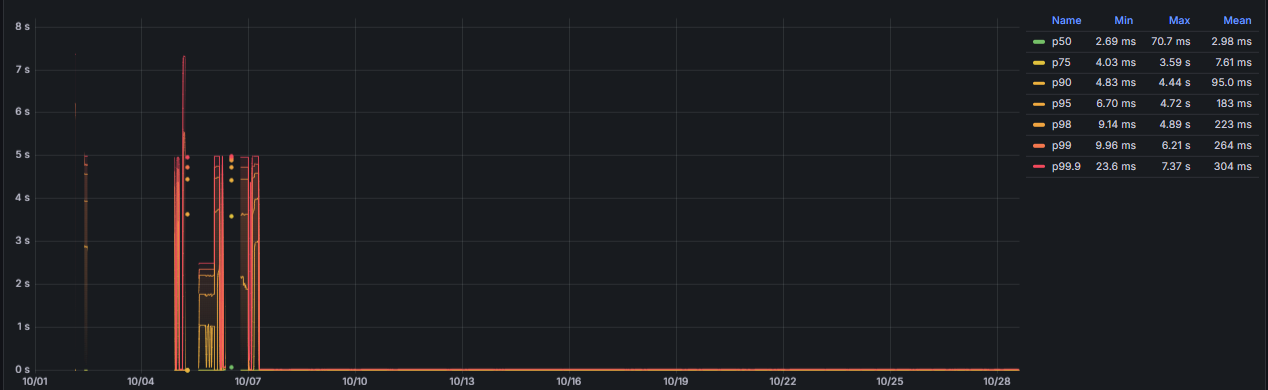
Understanding how LSM Trees work proved useful in an unexpected situation. In my team, we use Grafana dashboards backed by VictoriaMetrics to track system performance, and one of our KPIs is based on P95 latency. At one point, our Product Owner reported that, at the end of the month, the performance metrics for the first week appeared poor. There were unusual spikes and gaps (missing data) in P95 even though the system had been stable at that time, making the metrics unreliable and difficult to explain.
After going through the VictoriaMetrics documentation and one of the official blogs, I learned that it uses a storage model similar to an LSM Tree. Data is written in batches, organised into big and small parts, stored across multiple files, and later merged through compaction. More importantly, data deletion is not immediate. When data exceeds the retention period, it is not removed instantly. Instead, it is gradually cleaned up during background merge processes, typically when the entire part is fully out of the retention range.
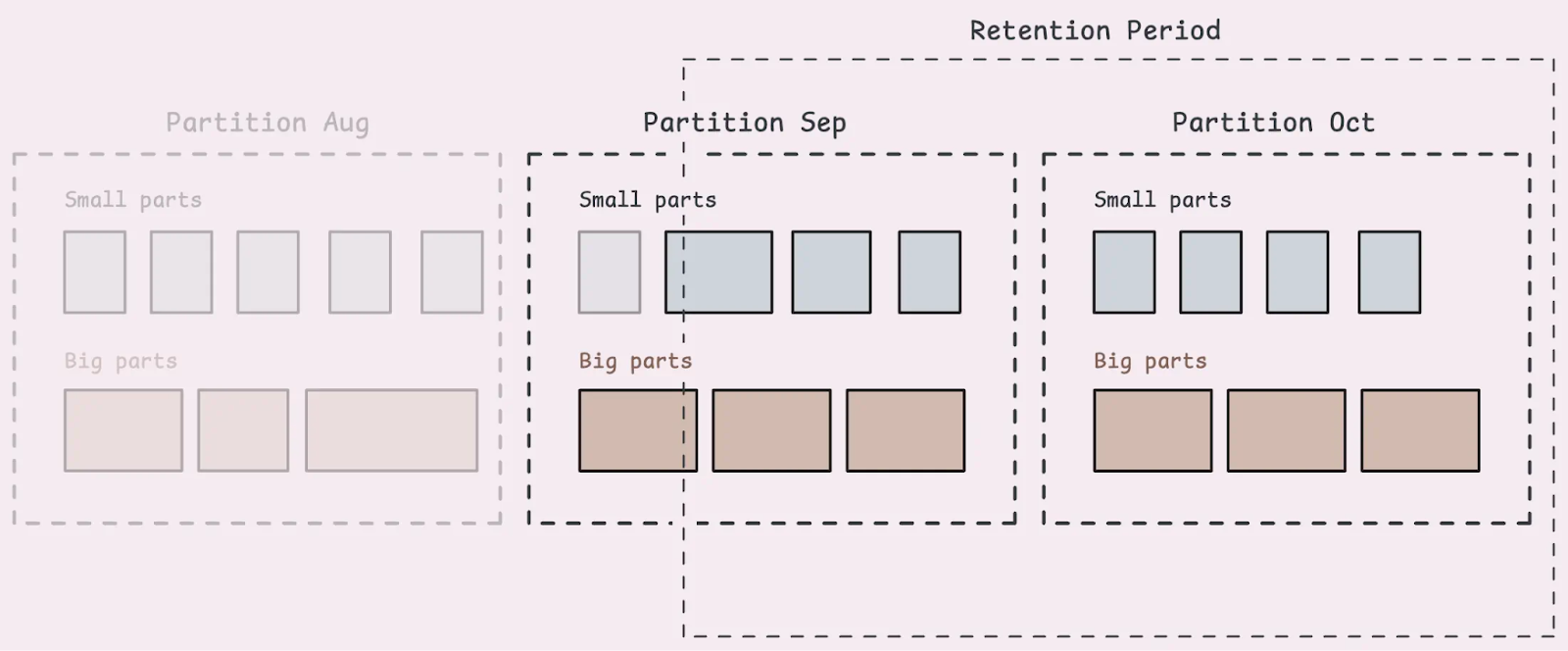

In our case, the retention period was set to 21 days. This meant that data older than 21 days could still partially exist in the system until compaction completed. As a result, queries over older time ranges could read partially deleted data, which explains why there were missing data points (due to partial deletion) and unexpected spikes (also due to partial deletion, causing skew in the P95). Once I understood this behaviour, the issue became much easier to reason about. The spikes were not caused by the application, but by how the underlying storage engine handled delayed deletion and compaction.
Closing Thoughts
In this article, we explored how B+ Trees and LSM Trees work, how they handle reads and writes, and the trade-offs they make. B+ Trees optimise for efficient reads and predictable performance, while LSM Trees prioritise fast writes by batching and deferring work through compaction. Both come with their own complexities, from page management and caching to background maintenance processes.
As application developers, we rarely implement these data structures ourselves. However, understanding how they work helps us make better decisions when choosing technologies and, more importantly, helps us debug real-world issues. As seen in the example above, problems that appear to be application bugs can sometimes be explained by the behaviour of the underlying storage engine.
The main takeaway is simple. You do not need to build these systems to benefit from them, but having a mental model of how they work can save you a great deal of time and confusion. Sometimes, the difference between guessing and knowing comes down to understanding what is happening beneath the surface.
