Hi, I am Ziyi. I am a full-stack developer specializing in backend and platform development, with hands-on experience in distributed systems, observability, performance tuning, and service modernization. My work focuses on building scalable and reliable systems with technologies such as .NET, Kubernetes, Redis, MongoDB, and OpenTelemetry, while continuously improving engineering practices through real production experience.
A technical deep dive into how we evolved a critical shared platform from a tightly coupled monolith into a more observable, scalable, and resilient service ecosystem—while preserving delivery speed through disciplined Agile engineering.
For years, our core accounting system was the backbone of multiple product integrations and financial operations. It was stable, battle-tested, and capable of sustaining peak load across 22 VMs. But long-term stability can sometimes mask architectural fragility. In 2024, repeated database connection issues to the primary account database exposed a structural weakness in the old design: too many responsibilities were concentrated behind one shared system boundary, and too many downstream services depended on it. When that boundary became unstable, the blast radius extended across products.
That was the real starting point of Accounting System V2.
This was not a vanity rewrite. It was not about adopting microservices because the industry likes microservices, or moving to Kubernetes because cloud-native is fashionable. It was a response to a concrete systems problem: how do we reduce shared failure domains, lower database pressure, improve troubleshooting, and still keep engineering delivery efficient enough to support a fast-moving product organization?
The answer became a broader platform transformation. Accounting System V2 introduced service decomposition, token-based authentication and authorization, rate limiting, distributed observability, in-memory and Redis-backed caching, local developer orchestration with Aspire, and a more disciplined rollout strategy. More importantly, it demonstrated how an engineering team can use Agile practices not just to ship features, but to evolve platform architecture safely and incrementally.
Starting from the real bottleneck, not from theory
The earliest plan was relatively small in scope: migrate selected endpoints out of the legacy shared service and into independently deployable services. That would already have improved maintainability and reduced release coupling. But once the team began mapping dependencies and investigating production behavior more closely, it became obvious that the issue was not simply endpoint ownership. The entire operational model needed improvement.
The old architecture had several constraints that became harder to tolerate as traffic and business complexity grew. It relied heavily on synchronous flows. It lacked sufficient caching in performance-sensitive paths. It concentrated traffic on shared database access patterns. It made horizontal scaling and isolated deployments harder than they should be. And when production incidents occurred, tracing cross-service behavior was far more difficult than it needed to be.
The target state for Accounting System V2 therefore expanded beyond “split some services.” It became a platform program with explicit engineering goals: lower database load, improve latency, strengthen resilience, reduce support friction, and make production behavior visible through telemetry rather than inference. That shift in framing mattered. It meant the team was no longer optimizing code in isolation; it was redesigning the operating characteristics of the system.
Re-shaping the platform surface
At the architectural level, Accounting System V2 moved toward a service-oriented topology with clearer boundaries around concerns such as token management, transaction workflows, member access, statements, and wallet-related operations. The key gain was not only modularity, but control over blast radius.
Under the old model, one shared service and shared database path could become the choke point for many products. Under the new model, services can be deployed, scaled, observed, and tuned more independently. This does not eliminate complexity—distributed systems always trade one kind of complexity for another—but it makes that complexity more manageable because it is explicit.
The team also paid attention to communication overhead inside the cluster. Rather than routing every internal service call through external balancing layers, inter-service traffic was optimized through headless service patterns within the RKE cluster. That gave clients more direct access to pods and reduced unnecessary proxy traversal. It is a subtle but important point: platform performance is not only about application code or SQL. Network path design matters too.
At the same time, the team recognized the trade-offs. Long-lived gRPC or HTTP/2 connections can affect balancing characteristics, and cluster networking has its own overhead compared with a simpler VM-based model. Accounting System V2 did not pretend those trade-offs do not exist. Instead, it designed around them, using communication-path tuning, caching, thread-pool adjustments, and focused optimization of the hottest flows.
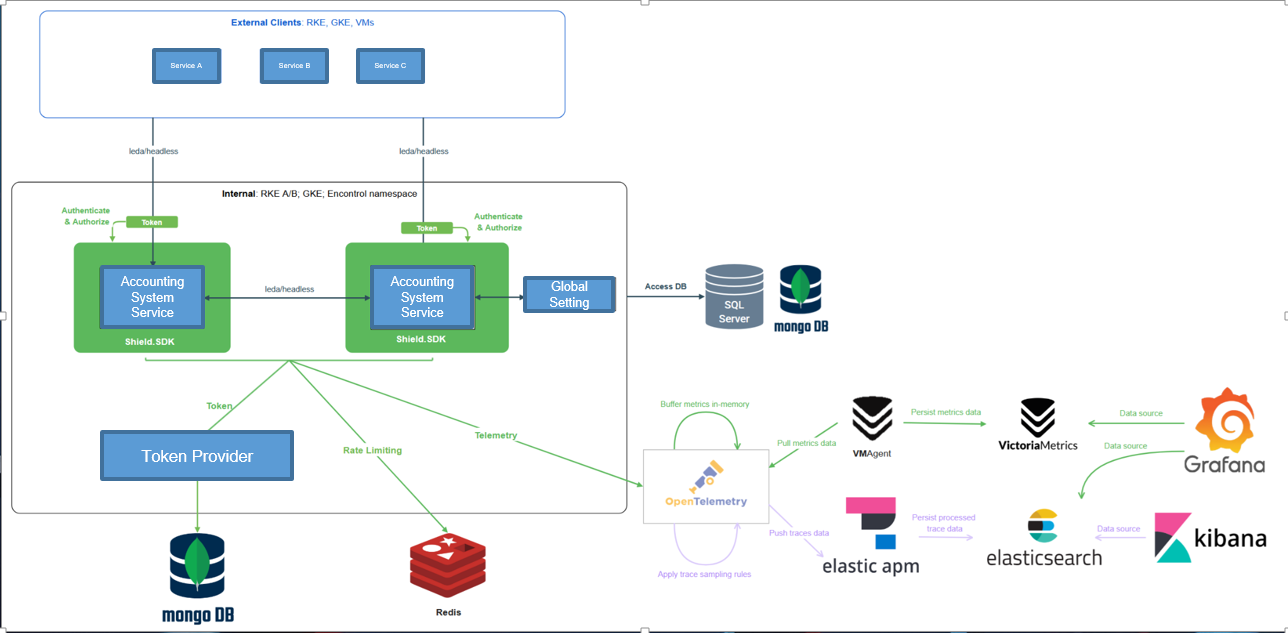
Figure 1 Account System V2 architecture overview
Performance work that came from production behavior
One of the strongest examples from the project is the balance retrieval path for one of our external service-provider integrations. This was not a synthetic benchmark invented for a slide deck. It was a real workload pattern with real performance consequences.
The original implementation depended on a heavy aggregation view to compute balance. That became expensive for large account populations under a single hierarchy. In one case, the hierarchy contained more than 200,000 accounts, which made the balance query path far from lightweight.
Instead of accepting the view as fixed, the team reworked the path by splitting the logic into separate stored procedures for calculations, and then summing the results in the application layer. That reduced query time from around 2 seconds to roughly 0.9 seconds. The work did not stop there. Because 0.9 seconds was still too slow for a performance-critical flow, the design then evolved again: read this balance from the secondary account database when appropriate, keep primary reads for time-sensitive operations such as transaction submission and limit checks, and cache the balance in Redis for three seconds via a background job.
This is a good example of mature performance engineering because it is layered. First, reduce the cost of the SQL. Then separate read paths by business criticality. Then add short-lived caching to absorb repeated reads. The result is not merely faster code. It is a clearer understanding of where freshness matters, where eventual consistency is acceptable, and how to protect the primary database from avoidable load.
Caching as a control-plane strategy, not just a speed trick
Caching in Accounting System V2 is not limited to hot business data. It also plays a foundational role in platform control paths.
Permission-control and rate-limiting metadata are stored in MongoDB, but the client-side services and the server-side token provider use scheduled background jobs to pull that metadata from MongoDB and materialize it in in-memory dictionaries for O(1) lookup during request processing. This keeps authentication, authorization, and rate-limiting checks cheap at runtime.
That design choice matters for two reasons. First, it makes latency more predictable because the request path depends less on external store round-trips. Second, it protects MongoDB from turning into a bottleneck as more services participate in token validation and permission evaluation. In effect, the team moved configuration and policy data out of the hot request path and into an in-memory control plane.
For a shared platform, this is exactly the right instinct. Many systems scale poorly not because business logic is too complex, but because policy evaluation is allowed to remain expensive and centralized. Accounting System V2 avoids that trap.
A stronger security model embedded into the platform
Another major improvement in V2 is the introduction of a token provider together with Shield-based authentication, authorization, and rate limiting. The purpose was not merely to add a token header. It was to formalize the relationship between callers and shared platform services.
Projects register with the platform and receive an x-api-key. The token is mapped to the corresponding project and is not intended to be secret in the same way as a traditional credential. The actual control comes from registration, permission mapping, and server-side validation. Once registered, callers can be authenticated, authorized for specific features, and rate-limited according to platform-defined rules.
This design brings order to a class of problems that often stays informal for too long in internal platforms. Without strong caller identification, teams struggle to answer simple but operationally critical questions: who is calling this endpoint, at what rate, under what permission scope, and which caller should be throttled or disabled if something goes wrong? Accounting System V2 turns those questions into platform capabilities instead of ad hoc detective work.
The engineering discipline is visible in the details. The Shield SDK uses Redis-backed distributed rate limiting for high-throughput enforcement. A background job collects remaining quota and bucket limits from Redis and exposes them through metrics. The additional middleware overhead is small enough to be acceptable in practice, while the protective value for shared infrastructure is substantial. Even better, the system is built with graceful degradation in mind: when Redis is unhealthy, health checks allow the rate-limit logic to back off rather than turning a cache dependency into a service-wide outage.
That is the right kind of resilience mindset. Platform protection is important, but platform protection must itself fail safely.
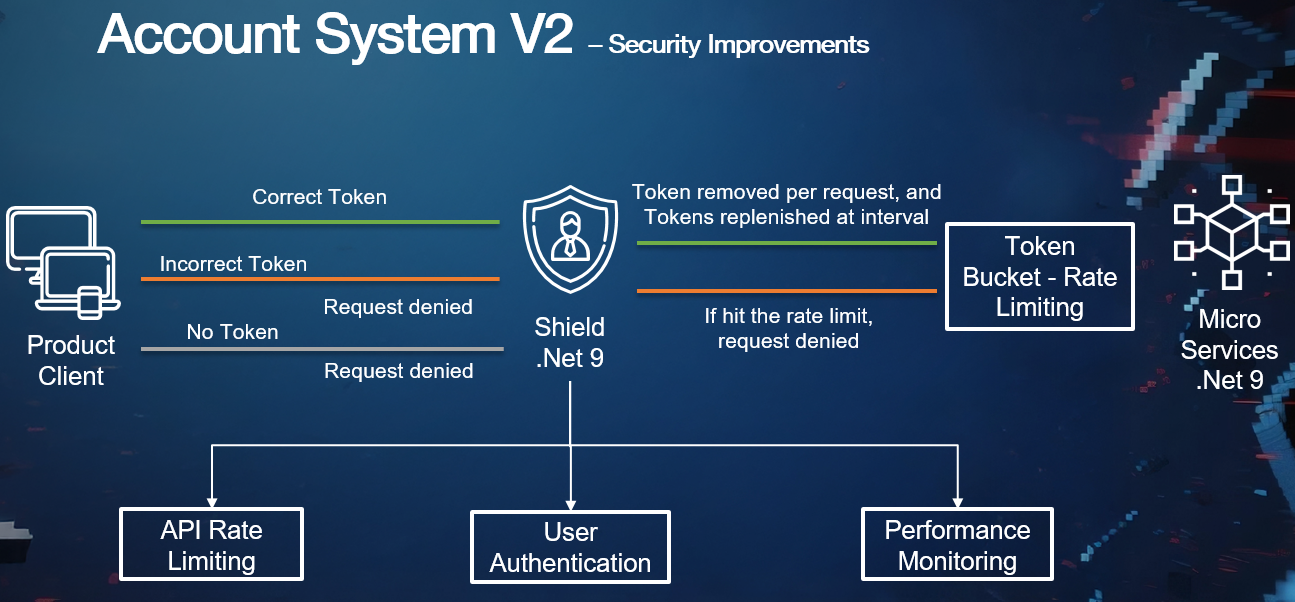
Figure 2 Security model with Account Token Provider and Shield SDK
Observability as part of the architecture, not an afterthought
A distributed platform without observability is just a more complicated failure surface. One of the clearest advances in Accounting System V2 is the way telemetry was made a first-class architectural component.
The observability stack includes OpenTelemetry instrumentation in .NET services, OpenTelemetry Collector for telemetry routing, VictoriaMetrics for metrics storage, Elastic APM Server for traces, and visualization through Grafana and Kibana. The system also standardizes structured logging with TraceId correlation so that traces and logs can be followed together instead of examined in isolation.
This enables the team to monitor the system at the right levels of abstraction. Metrics can surface trends such as rising latency, request spikes, rate-limit saturation, thread-pool stress, or error bursts. Traces can identify whether the slowdown sits in the application layer, Redis, MongoDB, gRPC paths, or SQL calls. Logs provide the lower-level execution context to explain what happened inside those spans.
The result is a shorter path from symptom to diagnosis. That matters especially in a platform setting, where support engineers and developers often work under time pressure and with incomplete context. A good dashboard is useful, but a good dashboard linked to correlated traces and logs changes the quality of operational response. It reduces guesswork, speeds mitigation, and makes post-incident analysis more concrete.

Figure 3 Grafana can display caller info
Figure 5 Trace endpoint whole data flow by TraceId
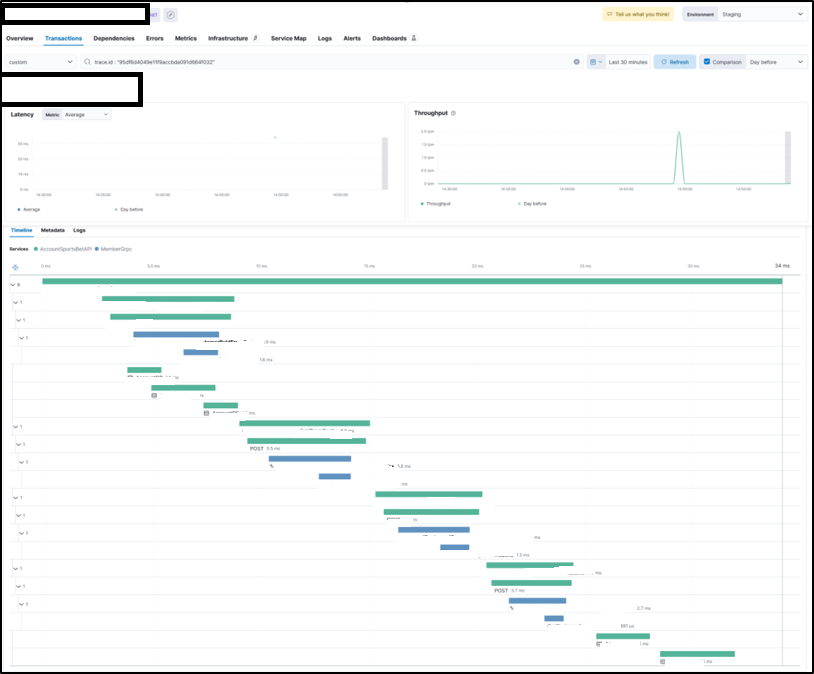
Figure 6 APM Tracing across multiple services
Learning from instability, not just from clean-room design
The stability work around the platform reinforces why this re-architecture was necessary. In 2025, the team investigated high-priority incidents involving sharp drops in transaction volume and database pressure related to heavy bursts of insert and update traffic. One recurring pattern was last-page latch contention on high-traffic tables, which caused stored procedures to timeout and drove up overall database latency.
That kind of incident is easy to misread as a purely DBA problem. In reality, it is a system-design problem. Burst traffic patterns, insert hotspots, timeout behavior, service retry strategies, and synchronous dependency chains all contribute to how severe the outcome becomes. Accounting System V2 addresses these concerns not through one silver bullet, but through a combination of decomposition, observability, caching, query-path redesign, and controlled rollout.
This is a useful reminder for platform engineers: resilience does not usually come from any single technology choice. It comes from shaping the system so that unavoidable pressure is absorbed and localized instead of amplified.
Kubernetes, with trade-offs understood
A technically credible platform discussion should acknowledge that Kubernetes introduces overhead. Compared with running directly on VMs, containerized workloads can show higher tail latency because of overlay networking, scheduler behavior, container-runtime layers, and shared-node contention. Our decision to adopt Kubernetes was therefore based on measured behavior rather than architectural preference alone.
In load testing, a production-like setup with 800m CPU request / 1 CPU limit and 700Mi / 1000Mi memory for one API pod, together with 800m CPU request / 2 CPU limit and 500Mi / 1000Mi memory for one gRPC pod, sustained 200 RPS at 100% success rate, with latency holding at approximately p95 14.62 ms. Beyond that point, the limits of a single pod became visible. At 250 RPS, p95 latency rose to 203.01 ms, and at 300 RPS it degraded to 49.53 s, with failed checks and dropped iterations. After scaling out to two pods, the same workload improved substantially: at 250 RPS, p95 latency dropped to 20 ms, and at 300 RPS it improved from 49.53 s to 210.32 ms, while requests returned to full success

Figure 7 Load Test Comparison
These results clarified the real trade-off. Kubernetes was not chosen because it produced the lowest single-instance latency. It was chosen because it provided the operational model the platform needed: horizontal elasticity, failure isolation, safer rollouts, and more standardized runtime control. That decision was reinforced by the engineering work around it—thread-pool tuning to keep workers warm under load, optimized service communication, added cache layers, stronger observability, standardized local orchestration, and progressive rollout strategies to reduce deployment risk. Infrastructure abstraction does not remove the need for optimization; it makes disciplined optimization even more important.
Developer velocity as a platform requirement
One of the best signals of engineering maturity in this project is that developer experience was treated as part of system design. The team invested in local development with .NET Aspire and containerized DevDB so developers could run multiple services locally with one-click startup, inspect credentials and connection strings, open Redis Insight, Kafka UI, and Mongo Express, perform local metadata migration, and examine logs, traces, and metrics in a self-contained environment.
This has an outsized effect on delivery quality. A platform is easier to evolve when engineers can reproduce realistic conditions without depending on shared staging environments for every change. Faster feedback improves experimentation. Local observability improves debugging. Better environment parity reduces “works on my machine” drift. And when those local workflows are shared across the team, knowledge becomes less siloed.
This is where the Agile culture behind Accounting System V2 becomes visible in the day-to-day mechanics. The project was supported by spike work, workshops on OpenTelemetry and Aspire, shared documentation, clearly stated goals, measured iteration, and rollout plans that included recovery paths. That is Agile in the engineering sense: not just sprint ceremonies, but a culture of learning, decomposition, observability, reversibility, and frequent feedback.
Shipping safely in a sensitive, high-throughput domain
In high-throughput systems, release quality is not defined only by whether code compiles or whether a test suite passes. It is defined by whether change can be introduced without destabilizing shared infrastructure. That principle shaped how Accounting System V2 was rolled out.
The team used progressive delivery to start with a small percentage of traffic, review metrics, and ramp up only after confidence increased. Separate deployments and secondary database reads were used as safety measures during performance validation. Monitoring was not treated as a post-release activity; it was part of the release gate itself. Response-time trends, quota consumption, error thresholds, CPU throttling, and trace behavior all became inputs to go/no-go decisions.
The team also complemented platform rollout with data-integrity checks and operational SOPs. When migrating endpoints from the legacy service to the new stack, engineers did not rely only on functional correctness in isolation. They also verified response time and output consistency across environments, discussed monitoring windows for migrated endpoints, and prepared rollback mechanisms to restore the earlier path if needed. In sensitive domains, confidence is built through evidence, not optimism.
More than a rewrite
Accounting System V2 ultimately matters because it changed more than the deployment topology. It changed how the platform behaves under load, how callers are governed, how failures are diagnosed, how developers work locally, and how production changes are introduced.
It reduced dependency on a single shared monolith. It lowered unnecessary database pressure through smarter data-access patterns and in-memory policy caching. It formalized authentication, authorization, and rate limiting for internal callers. It made telemetry usable at the point of support and debugging. It improved local development ergonomics. And it embedded resilience into the platform contract, not just into incident response.
That is the broader lesson for developers across the company. Strong internal platforms are not built through one big architectural gesture. They are built through a series of concrete engineering choices that connect directly to operational reality: identifying a true bottleneck, instrumenting it, redesigning it, shipping it incrementally, and learning from the result.
Accounting System V2 is a strong example of that discipline in action. It shows what happens when a team treats architecture, reliability, observability, security, and developer workflow as parts of the same engineering system. And that, more than any single technology in the stack, is what makes the platform stronger.
