How Server-Side Rebalancing Eliminates Your Biggest Kafka Headache
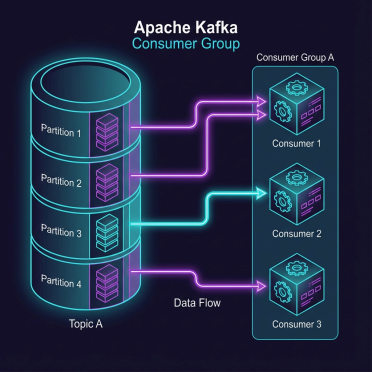
If you are new to Apache Kafka, you’ve likely mastered the basics: Producers write data to Topics, and Consumers read that data. You probably also know that to scale up, you put multiple consumers into a Consumer Group to share the workload.
It sounds magical. You have a topic with 10 partitions. You start 5 consumers in a group. Kafka automatically gives 2 partitions to each consumer. Perfect balance.
But what happens when one of those consumers crashes? Or what happens when Black Friday arrives, and you suddenly add 5 more consumers to handle the load?
Kafka has to redistribute the work. Partitions must be taken away from some consumers and given to others. This process is called Rebalancing.
For years, rebalancing was the boogeyman of Kafka administration—a necessary evil that caused latency spikes and headaches. But with the advent of modern Kafka (specifically the era of KRaft and KIP-848, standard in Kafka 4.0+), this beast has been tamed.
Let’s dive into the bad old days of “Classic Rebalancing” and compare it to the shiny new world of “Server-Side Rebalancing.”
1. The Bad Old Days: The “Classic” Way (Client-Side)
Before modern Kafka, rebalancing was a “Client-Side” process.
This means the Kafka broker (the server) didn’t actually decide who got which partition. The broker was just a coordinator; it was up to the consumers themselves (your application code) to figure out the assignments.
Think of it like a chaotic dinner party where the host (the broker) tells the guests (the consumers), “Figuring out the seating chart is your problem. Don’t start eating until everyone agrees on their seat.”
The “Stop-the-World” Flow

The classic protocol relied on a process that was incredibly disruptive. Here is the step-by-step sequence when a new consumer joins:
- The Trigger & The Freeze: A new consumer joins. The Broker signals every existing consumer to stop. Your entire application pauses processing data.
- JoinGroup (The Roll Call): Every consumer sits idle and sends a JoinGroup request to the Broker, waiting for instructions.
- Electing the Leader: The Broker picks one consumer randomly to be the “Group Leader.”
- The Math (Client-Side Logic): The Broker sends a list of everyone in the group to that Leader. Now, your application client library runs a complex algorithm to figure out fair partition assignments.
- SyncGroup (The Distribution): The Leader sends the final plan back to the Broker, which then distributes it to everyone.
- Resume: Only now do consumers start processing data again.
Visualizing the Classic Nightmare
Below is a sequence diagram showing time moving from top to bottom. Notice the massive red block where actual work stops.

2. What Were the Problems in the Classic Way?
If that diagram looks inefficient to you, you’re right. It was painful for three main reasons:
- The Latency Spike (Stop-the-World): Look at the large red shaded area in the diagram above. During that entire time, your application is doing zero work. In large groups, this pause could last tens of seconds.
- “Thick” Clients and Inconsistency: Because the “Calculation” happened in the client (Step 11 in the diagram), every language SDK (Java, Python, Go) had to implement complex logic. Bugs in client libraries caused massive headaches.
- Rebalance Storms: Because the Leader needs the full member list to calculate, the group must fully stabilize before the red phase can end. If 10 consumers start up one after another, you might trigger 10 sequential stop-the-world events.
3. The Brave New World: Server-Side Rebalancing (KIP-848)
In modern Kafka (Kafka 4.0+ defaults), the paradigm flipped. We moved to Server-Side Rebalancing.

The Broker (supported by the super-fast KRaft metadata engine) is now the boss. It doesn’t ask the clients to figure out the seating chart; it tells them where to sit, one by one.
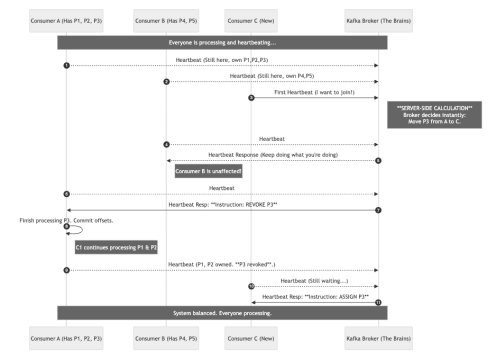
The Incremental Heartbeat Flow
The new way is smarter and incremental. It relies on the continuous “heartbeats” that consumers already send to the broker just to say “I’m alive.” It piggybacks instructions onto these heartbeat responses.
Here is the new flow when Consumer C joins an existing group of A and B:
- The Continuous Loop: Consumers A and B are happily working, sending periodic heartbeats to the Broker.
- Server-Side Calculation (Instant): Consumer C sends a heartbeat to join. The Broker, holding all the logic, immediately calculates that it needs to move Partition 3 from A to C.
- Incremental Instructions: The Broker does not yell “STOP”. It waits for A’s next regular heartbeat and responds: “Keep working, but please revoke Partition 3.” Consumer B is totally unaffected.
- The Handoff: Consumer A finishes its current batch for Partition 3 and confirms the revocation in its next heartbeat.
- Assignment: Only then does the Broker tell Consumer C: “Okay, you are now assigned Partition 3.”
Visualizing the Modern Flow
Notice in the diagram below how there is no giant “Stop” block. Consumer B continues processing uninterrupted, and the handover between A and C happens via standard background chatter.
Summary: How the New Way Solves the Problems
The shift to Server-Side incremental rebalancing solves the historical pain points of Kafka.
| The Classic Problem | The Modern Solution |
| Stop-the-World Pauses: The entire group halts processing to coordinate. | Incremental Rebalancing: Only the specific consumers swapping partitions are momentarily affected. Everyone else keeps working. Near-zero downtime. |
| Thick Clients: Complex logic in the client SDK. | Thin Clients: The complex logic is centralized on the Kafka Broker. Clients just follow simple heartbeat instructions. |
| Rebalance Storms: Group must stabilize before calculation. | Continuous Reconciliation: The server constantly adjusts towards the desired state in small steps. |
4. The Real-World Numbers (Classic vs. New)
Theory is nice, but let’s talk about real production impact.
In one of our projects, a single consumer group has ~150 consumers running on Kubernetes. During a deployment, K8s performs a rolling update—replacing pods one by one.
On the classic protocol, every single pod restart triggers a “Stop-the-World” rebalance for the entire group. With 150 pods constantly joining and leaving, the group enters a continuous “rebalance storm.” The result? A full deployment can cause the system to stall for 10–15 minutes before it finally stabilizes.
After upgrading to the new consumer group protocol, the difference was night and day. Rebalancing became almost instant. Existing consumers kept running, and only the members that were joining or leaving spent a few seconds finishing the handoff. In practice, that join/leave window is usually under 5 seconds.
We went from “schedule a maintenance window” to “deploy whenever you want.”
5. Upgrading Kafka Without Harming Production
There isn’t one perfect upgrade playbook. The right path depends on your tolerance for data loss versus latency. Here are the three standard patterns we used to navigate these waters.
Strategy A: The “Direct Cutover” (Fast, Higher Risk)
- Spin up the new cluster.
- Pre-create topics with the correct configs.
- Hard switch: Point producers and consumers to the new cluster immediately.
Verdict: This is the “rip off the band-aid” approach. It’s the fastest route, but you accept a brief gap in data availability and potential data loss for in-flight messages during the cutover. Best for dev/staging environments or non-critical systems who allow some data loss.
Strategy B: The “Sequential Transition” (Safe but Delayed)
- Switch producers first to the new cluster.
- Drain the old cluster: Let consumers finish processing all existing messages on the old cluster.
- Switch consumers to the new cluster only after the old queue is empty.
Verdict: You keep every message (zero data loss), but the draining step introduces a processing delay (latency). This is ideal for batch jobs or systems where real-time freshness isn’t critical.
Strategy C: The “Dual-Consumer” (Zero Downtime)
- Dual-read consumers: Update your consumers to read from both the old and new clusters simultaneously.
- Switch producers to the new cluster.
- Drain and remove: Once the old cluster is empty, simply remove the old-cluster config.
Verdict: This is the gold standard for mission-critical apps. It ensures zero data loss and minimal latency, though it requires slightly more complex consumer logic to handle two sources at once.
One Crucial Detail: Check Your Protocol
When you upgrade consumers, double-check that the new consumer group protocol is actually enabled in your client configuration.
By default, many clients still validly set group.protocol to classic to maintain backward compatibility. This means even if you are on Kafka 4.0, your consumers might still be using the old “stop-the-world” logic!
To enable the new KIP-848 benefits, you must explicitly set:
group.protocol=consumer
Without this, you are driving a Ferrari engine with the parking brake on.
